データレイクとしてのクラウドオブジェクトストレージ
クラウドを活用したデータレイクで、オンプレミス機器の費用と複雑さを回避しましょう

膨張する世界のデータ量
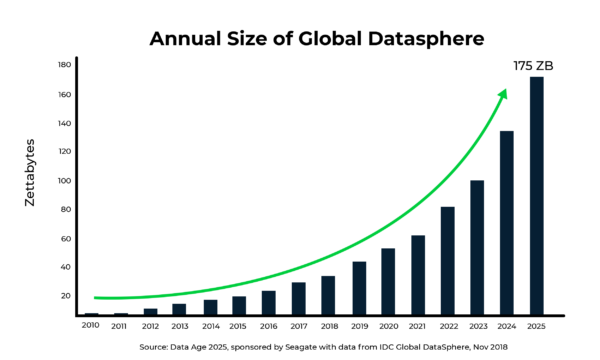
データ量は爆発的に増加しています。増え続けるモバイルデバイス、インテリジェントセンサー、スマートエンドポイントにより、データの種類や量は増加し、そして速いスピードが求められています。IDC社の調査では、接続デバイスやスマートシステムの急増に伴い、世界の年間データ生成量は、2018年の33ゼタバイト(ZB)から急増し、2025年には175ZBに達すると予測しています。(1ZB = 1兆GB)。
この膨大な生データから実用的な洞察を得ることで、企業はビジネスを加速させ、従業員の生産性を高め、業務を合理化することができます。企業は、データから得た洞察をもとに、ビジネスを最適化し、販売やマーケティング活動、広告キャンペーンを調整することができます。自治体や公益事業者は、公共の安全とサービスの向上、交通とエネルギーシステムの最適化、経費や廃棄物の削減を実現できるでしょう。研究者や科学者は、宇宙に対する理解を深め、病気の治療法を開発し、天気予報や気候モデルを改善できるかもしれません。
ビッグデータは、産業全体を大きく変革する可能性を秘めています。しかし、時代遅れの高価なデータストレージソリューションがその変革の邪魔をしています。多くの企業は従来のオンプレミス型ストレージや、第一世代クラウドストレージ ベンダーは、膨大なデータ量を長期にわたり保管できていないという実情があります。多くの企業は、主要なビジネスアプリケーションや、規制要件を順守するために必要なデータのみを保存しています。顧客の行動や市場の動向に関して、貴重な洞察を得られるかもしれない過去のデータは、廃棄されていることもしばしばあります。
しかし、この現状は変わりつつあります。新世代のクラウドストレージが登場し、シンプルなクラウドストレージを低価格で使用できるようになりました。Cloud 2.0のストレージでは、データの種類や目的、期間を問わず、WasabiのHot Cloud Storageに低価格で保存することができます。また、どのデータを収集し、どこに保存し、どの程度の期間保持するかといった煩わしい判断をする必要もなくなります。
この次世代のクラウドストレージは、データレイクの構築に理想的だと言えます。TDWIが250人以上のデータ管理の専門家を対象に行った調査では、回答者の約半数が、既にデータレイクを運用している(23%)、または1年以内に運用を開始する予定(24%)であると回答しています。
概要
データレイクとは?
データレイクとは、異なる種類のデータをそのままの形式で安全に保存するための企業向けのデータ管理システムです。データレイクに保管されるデータには、従来の構造化データや半構造化データだけでなく、様々な種類のデータ(センサーデータ、クリックストリームデータ、ソーシャルメディアデータ、ロケーションデータ、サーバーやネットワークデバイスのログデータなど)が含まれます。データレイクは、企業の全てのデータを単一のリポジトリに集め、スキーマやデータ変換のような従来の制約や手間をかけずに分析することで、企業情報のサイロ化を解消することができます。
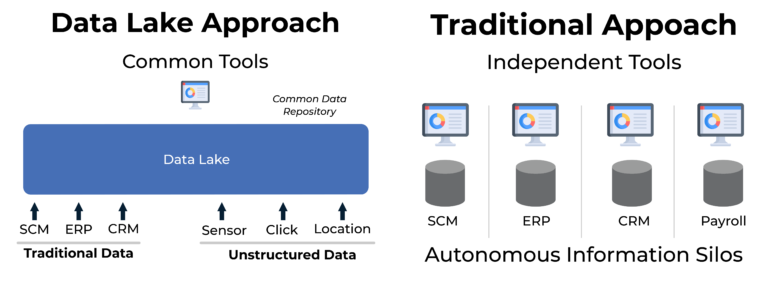
データレイクは、高度な分析、機械学習、新しいデータ駆動型ビジネスの基礎となります。データサイエンティスト、ビジネスアナリスト、技術者は、ビジネス用またはオープンソースのデータ分析及び可視化し、ビジネスインテリジェンスツールを使用して、その場で分析を行うことができます。数多くのベンダーが、非技術系ユーザー向けのセルフサービス型データ探索ツールや、データサイエンティスト向けの高度なデータマイニングプラットフォームを標準ベースのツールとして提供しており、企業がデータレイクへの投資を収益化し、生のデータを事業場の価値に変換できるよう支援しています。
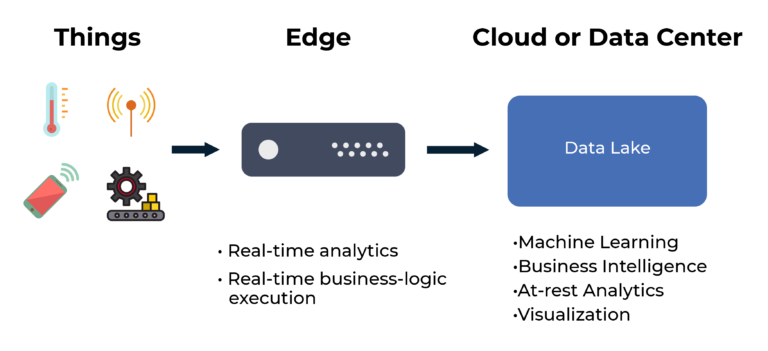
下の図は、Internet of Thingsの実装におけるデータレイクを表しています。エッジ コンピュート デバイスは、データレイクに送信する前にローカルデータを処理・分析します。例えば、エッジサーバーはリアルタイム分析、ローカルビジネスロジックの実行、また価値のないデータのフィルタリングを行います。
データウェアハウス vs データマート vs データレイク
データレイクとデータウェアハウスという言葉はよく混同され、同じような意味合いで使われることがあります。実際には、どちらも巨大なデータを保存するために使用されますが、データレイクとデータウェアハウスは本質的に異なります(補完し合うことも可能です)。
データレイクは、構造化、半構造化、非構造化などあらゆるタイプのデータを保管することができる巨大なデータプールです。
データウェアハウスは、特定の目的のために既に処理・構造化され、フィルタリングされたデータのためのリポジトリです。言い換えれば、データウェアハウスはきちんと整理され、明確に定義されたデータを保管しています。
データマートは、データウェアハウスの一部であり、サプライチェーン管理アプリケーションなど特定の目的のために、特定の企業の事業部門によって使用されます。
データレイクという言葉の発案者であるJames Dixonは、その違いを例えで次のように説明しています。「データマートを、消費しやすいように洗浄・包装・構造化されたペットボトルに入った水と例えると、データレイクはより自然な状態の大きな水域と言えます。データレイクのコンテンツは、水源から流れ込んで湖を満たし、多くのユーザーが湖の水を調べたり、飛び込んだり、サンプルを取ったりすることができます。
データレイクは、データウェアハウスと組み合わせて使用することができます。例えば、データレイクをデータウェアハウスのランディングおよびステージングリポジトリとして使用することができます。データレイクを使用して、データを収集・処理した後に、データウェアハウスや他のデータ構造に投入することができます。
きちんと処理されていないデータレイクは、データにガバナンスや品質基準が適用されていない「沼」になる危険性があり、データを収集する価値を根本的に下げてしまいます。また、「沼」から収集したデータによってなされる意思決定は、妥当性や信頼性が低い可能性があります。
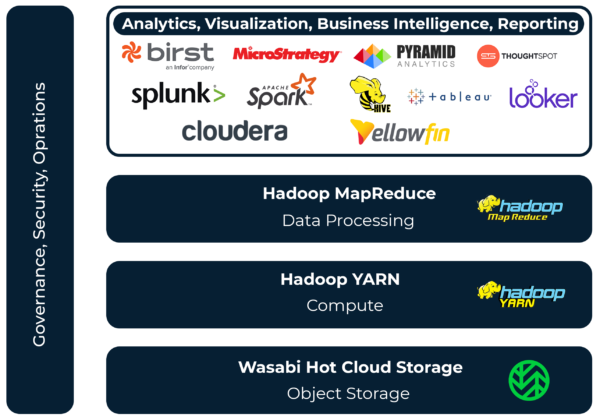
下図は、典型的なデータレイクの技術スタックを示しています。データレイクには、拡張可能なストレージとコンピュートリソース、データを管理するためのデータ処理ツール、データサイエンティスト、事業部門のユーザー、技術者向けの分析・レポートツール、共通のデータガバナンス、セキュリティ、運用システムなどが含まれます。

データレイクは、企業のデータセンターやクラウドに導入することができます。初期にデータレイクを導入した企業の多くは、オンプレミスで構築していました。データレイクが普及するにつれ、多くの主要な企業はクラウドベースのデータレイクに注目し、サービスインまでの時間の短縮、TCOの削減、ビジネスの俊敏性の向上を目指しています。
オンプレミスのデータレイクはCAPEXとOPEX集約的である
企業のデータセンターでは、一般的なサーバーとローカル(内部)ストレージを使用してデータレイクを実装しています。現在、多くのオンプレミス型データレイクでは、データプラットフォームとして、一般的なハイパフォーマンスコンピューティングフレームワークであるHadoopの商用版またはオープンソース版が使用されています。 (TDWIの調査では、回答者の53%がデータプラットフォームとしてHadoopを使用しており、リレーショナルデータベース管理システムを使用しているのは6%のみでした)。
数百台、数千台のサーバーを組み合わせて、拡張可能で耐障害性の高いHadoopクラスターを構築し、膨大なデータを保存・処理することができます。下図は、Apache Hadoop上でオンプレミスのデータレイクを実現するための技術スタックを示しています。

技術スタックは以下の通りです。
Hadoop MapReduce
一般的なハードウェアを使用した大規模クラスター上で、膨大なデータを並列処理するアプリケーションを、信頼性と耐障害性に優れた方法で簡単に記述するためのソフトウェアフレームワーク。
詳細はこちら
Hadoop YARN
ジョブスケジューリングとクラスタリソース管理のためのフレームワーク。
詳細はこちら
Hadoop 分散ファイルシステム(HDFS)
安価なディスクドライブを内蔵した低コストのサーバーで動作するように設計された高性能ファイルシステム。
詳細はこちら
オンプレミス型のデータレイクは、高いパフォーマンスと強固なセキュリティを提供するものの、導入、管理、保守、拡張が複雑であり、また高い費用が必要であることで知られています。オンプレミス型データレイクのデメリットは以下の通りです。
長期に渡るインストール
自社でデータレイクを構築するには、膨大な時間、労力、費用が必要です。システムの設計、アーキテクチャー、セキュリティ、管理システム、ベストプラクティスの定義と制定、コンピューティング、ストレージ、ネットワークインフラの調達、立ち上げ、テスト、全てのソフトウェアの選定、インストール、コンフィギュレーションが必要です。オンプレミスのデータレイクを本番環境で稼働させるには、一般的に数か月(多くの場合1年以上)かかると言われています。
高額なCAPEX
多額の設備投資により、ROIが低く、投資回収期間が長いビジネスモデルになっています。サーバー、ディスク、ネットワークなどのインフラは、ピーク時のトラフィック需要や将来の容量要件を満たすような過剰な設計となって、その結果、アイドル状態の計算リソース、未使用のストレージやネットワーク容量に対して常に不要なコストが発生しています。
高額なOPEX
電気代、空調代、ラックスペースにかかる費用、毎月のハードウェアメンテナンス費用、ソフトウェアサポート費用、ハードウェア管理費用などにより、機器の運用費用が高額になっています。
ハイリスク
事業の継続性を確保するためにセカンダリデータセンターにデータを複製することは、費用の観点から多くの企業にとっては難しい選択です。多くの企業は、費用を抑えるためにデータをテープやディスクにバックアップしています。大災害が発生した場合、システムを再構築し、業務を復旧させるのに通常数日から数週間かかります。
複雑なシステム管理
オンプレミスでのデータレイクの運用は複雑で難しいため、貴重で高価なITスタッフの労力を使用する必要があります。その結果、ITスタッフは戦略的な事業上の取り組みに注力することが難しくなります。
クラウドデータレイクは設備投資と複雑さを削減
パブリッククラウド上にデータレイクを構築することで、設備費用や運用に係る手間を省き、ビッグデータに関する取り組みを加速させることができます。クラウドベースのデータレイクの一般的な利点は次のとおりです。
サービスインまでの時間を短縮
インフラの設計作業、ハードウェアの調達、インストール、ターンアップタスクを省くことができるため、サービスインまでの時間を数ヶ月から数週間に短縮することができます。
CAPEXは不要
初期投資が不要なため、企業が本当に必要とするIT予算を確保することができ、他の投資に予算を回すことができます。
機器の運用費は不要
継続的な設備運用費(電気代、冷却費、賃料など)、ハードウェアの保守料金、定期的なシステム管理費などが不要になります。
スピーディーで無限の拡張性
オンデマンドでコンピュートとストレージ容量を拡張できるため、ビジネスの成長に合わせて容量を柔軟に拡張させ、顧客満足度を向上させることができます(事業部門の要望に迅速に対応可能)。
他のインフラから独立した拡張性
サーバー内部のストレージに依存するオンプレミスのHadoop実装とは異なり、クラウド実装では、コンピューティングとストレージの容量をそれぞれ独立して拡張することができます。これにより、拡張に係る費用を抑え、リソースを最大限に活用することができます。
リスクを低減
異なる地域においてデータを複製することで耐障害性を向上させ、大災害が発生した場合でも、事業を継続することが可能です。
IT運用をシンプルに
ITスタッフをインフラの運用から解放し、ビジネスを成長させるための戦略的タスクに集中させることができます。(物理インフラは、クラウドプロバイダーが管理します)
第一世代のクラウドストレージは、データレイクには高価で複雑すぎる
クラウドベースのデータレイクは、オンプレミスのデータレイクと比較すると、導入、拡張、運用がはるかに簡単で、費用も抑えることができます。しかし、第一世代のクラウドストレージは、本質的に高価であり(多くの場合、オンプレミスのストレージと同程度の費用が必要)、加えて複雑でもあります。多くの企業は、データレイクを導入するために、シンプルで低価格のストレージサービスを求めています。第一世代のクラウドストレージサービスのデメリットとして、以下が挙げられます。
高価で複雑なストレージ階層
レガシーなクラウドベンダーは、異なるタイプ(階層)のストレージサービスを提供しています。例えば、アクティブデータのためのプライマリストレージ、ディザスタリカバリのためのアクティブアーカイブストレージ、長期に渡ってデータを保存するための非アクティブアーカイブストレージなど、各階層は使用目的に応じて分かれています。それぞれの階層には、独自のパフォーマンス性能と耐障害性、SLA、価格設定があります。複数の価格変動要因を持つ複雑な料金体系では、適切なサービスの選択、費用予測、予算管理が困難です。
ベンダーのロックイン
各サービスプロバイダーは、独自のAPIをサポートしています。サービスを切り替えるには、既存のストレージ管理ツールやアプリケーションを書き換えや入れ替えが必要であり、時間と費用がかかります。さらに、レガシー・ベンダーはデータをクラウドから移動させるたびに、過剰なデータ転送(イグレス)料金を請求するため、プロバイダーを変更したり、複数のプロバイダーを組み合わせて利用したりすると高額な費用が発生します。
階層型ストレージサービスに注意
第一世代のクラウド ストレージ ベンダーは、複雑な階層型ストレージを提供しています。各ストレージ階層は特定の種類のデータを対象としており、パフォーマンス特性、SLA、価格プランが明確に分かれています。
各ベンダーのポートフォリオは若干異なりますが、これらの階層型ストレージは、一般的に3つの異なるデータに対して最適化されています。
アクティブデータ
オペレーティングシステムやアプリケーション、ユーザーが簡単にアクセスできるライブデータを指します。アクティブデータは頻繁にアクセスされるため、一般的に厳しい読み込み/書き込みのパフォーマンス要件があります。
アクティブアーカイブ
時々アクセスされるデータで、オンラインで即座に利用できるデータ(オフラインまたはリモートソースからの復元は行わない)を指します。例としては、災害復旧のためのバックアップデータや、短期間に時々アクセスする可能性のある大容量のビデオファイルなどがあります。
非アクティブアーカイブ
アクセス頻度の低いデータを指します。例として、規制遵守のために長期間保管されるデータなどがあります。一般的に、これらの非アクティブなデータはテープにアーカイブされ、オフサイトに保管されています。
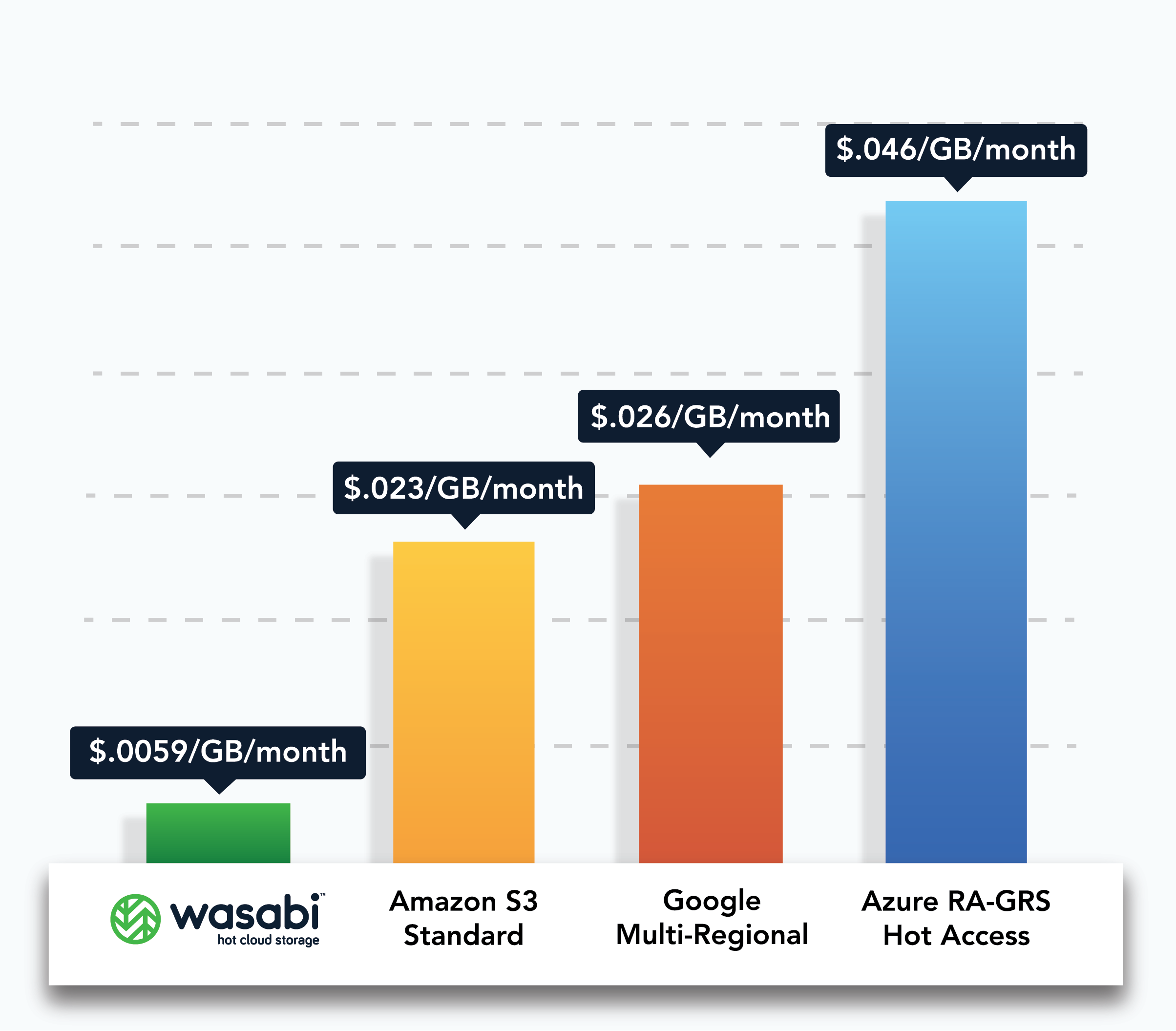
特定のアプリケーションのための最適なストレージを選定することは、従来のクラウドストレージでは非常に困難です。例えば、1つ例を挙げます。他社では4つの異なるオブジェクトストレージが提供されています。それぞれのオプションには、独自の価格設定とパフォーマンス特性があり、また一部のオプションでは、SLAと料金が異なる3つのストレージ層(ホットストレージ(アクセス頻度の高いデータ用)、クールストレージ(アクセス頻度の低いデータ用)、アーカイブストレージ(ほとんどアクセスされないデータ用))が提供されています。多くのオプションと価格変動要因があるため、十分な情報を得た上で意思決定を行い、正確な予算を立てることは非常に困難です。
Wasabiは、クラウドストレージはシンプルであるべきだと考えています。従来のクラウドストレージでは、ストレージの階層化や複雑な価格設定が行われていましたが、Wasabiは1つの製品で、あらゆるクラウドストレージの要件を満たす、予測可能で、手頃で、わかりやすい価格設定を提供しています。Wasabiは、アクティブデータ、アクティブアーカイブ、非アクティブアーカイブなど、どのようなデータでも使用することができます。
データレイクのためのWasabi Hot Cloud Storage
Wasabi Hot Cloud Storageは、あらゆる用途に対応できる、経済的で高速かつ信頼性の高いクラウドオブジェクトストレージです。複雑なストレージ階層や料金体系を持つ第一世代のクラウドストレージと異なり、Wasabiはシンプルで、高い費用対効果で拡張することができます。Wasabiは膨大な生データを保存するのに適しています。
データレイクとしてWasabiを利用する主なメリットは以下の通りです。
シンプルな価格設定
Wasabiの価格は、シンプルです。使った分を月額で支払うモデルまたは、予約容量制ストレージ(Reserved Capacity Storage, RCS)
を1年、3年、または5年単位で先行購入できるモデルの2つになります。
他社と異なりストレージからデータを抽出するための追加料金(エグレス料金)は不要です。また、PUT、GET、DELETE、その他のAPIコールにも追加料金は不要です。
優れたパフォーマンス
Wasabiの並列化されたシステムアーキテクチャは、第一世代のクラウドストレージと比較して、読み込み/書き込みのパフォーマンスを高め、TTFB(Time To First Byte)の速度を大幅に向上させます。
詳細は、パフォーマンスベンチマークレポートをご参照ください。(英語)
高いデータ耐久性と保護
Wasabiは、データの耐久性、完全性、安全性を徹底的に追求した設計になっています。オプションのデータ保護機能により、意図しない削除や管理上のミスを防ぎ、マルウェア、バグ、ウイルスからデータを保護し、また法規制へ準拠します。
Apache Hadoopデータレイク向けWasabi Hot Cloud Storage
Apache Hadoopでデータレイクを運用する場合、下図のように、HDFSの手頃な代替品としてWasabi を利用することができます。Wasabiは、AWS S3 APIと完全な互換性があります。オープンソースのApache Hadoopディストリビューションの一部であるHadoop Amazon S3Aコネクタを使用して、WasabiのようなS3およびS3互換のストレージクラウドを様々なMapReduceフローに統合することができます。
マルチクラウドでのデータレイク実装の一部としてWasabi を使用することで、サービスの選択肢を増やし、ベンダーロックインを回避することができます。マルチクラウドアプローチでは、データレイクのコンピュートリソースとストレージリソースは別々に拡張することが可能であり、最適なプロバイダーを利用することができます。
Wasabiは、Equinix、Flexential、Limelight Networksなどの大手コロケーション、キャリアホテル、エクスチェンジプロバイダーとの提携により、様々なクラウドコンピューティングサービスへのダイレクトで高速な接続を提供しています。これらのプライベートネットワーク接続は、インターネットの遅延やボトルネックを回避し、高速で予測可能なパフォーマンスを提供します。また、お客様のプライベートクラウドを直接Wasabiに接続することも可能です。 第一世代のクラウドストレージプロバイダーとは異なり、Wasabiダイレクトコネクトでは、データ転送(イグレス)料金は不要です。つまり、Wasabiから自由にデータを持ち出すこと可能なのです。
経済的に、事業継続性とディザスターリカバリーを確保
Wasabiは、異なる地域に分散した複数のデータセンターでホストされているため、耐障害性と高可用性を備えています。以下のように、Wasabiの異なる地域間でデータを複製することで、事業継続性の確保、ディザスタリカバリ、データ保護が可能です。
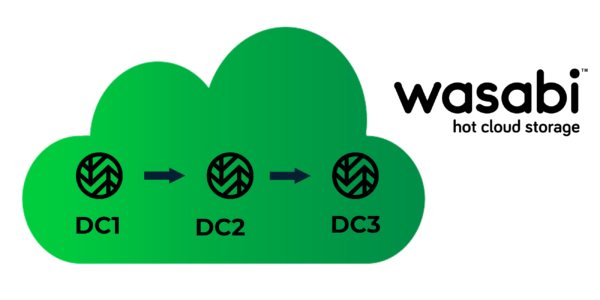
例えば、3つの異なる地域のWasabiデータセンターでデータを複製する場合、以下のように使用することができます。
- Wasabiデータセンター1:アクティブなデータストレージ(プライマリストレージ)
- Wasabiデータセンター2:バックアップとリカバリのためのアクティブ・アーカイブ(データセンター1にアクセスできない場合のホットスタンバイ)
- Wasabiデータセンター3:イミュータブルデータストア(管理上のミス、意図しない削除、ランサムウェアからのデータ保護)として使用します。イミュータブルデータオブジェクトは、Wasabiを含む誰からも削除や変更ができません。
まずは30日間の無料トライアル
登録は簡単。トライアル中はいつでも解約(キャンセル)することができます。
- ✅ 最大1TBのデータを30日間保存できます
- ✅ トライアル期間終了後の自動更新なし
- ✅ クレジットカード不要